Current hypes, trends and pushed business models at 2020
Let's take a short look at the current hypes, trends and pushed business models for companies:
- IOT (Internet of things), Industry 4.0
Machines, units, etc. know and probably send their own status at manufacturer, service center, at home or somewhere else over the rainbow (in case of ugly DNS injection, warped rouing tables [OSPF, BGP] ot men in the middle [squid bump, bluecoat, ...]).
Those units normally,communicate when they need maintenance, when components soon needs to be replaced, when physical, technical or environmental critical limit reached, when subsystems fail or completley shut down, when the user when the customer operates it improperly or negligently, simply report in intervals that they are alive and everything's OK, , etc
We can find a lot of use cases for many useful applications here, added value / surplus is often small but still useful! Problems with security, flood of data, extracting relevant events and, above all, reacting to the corresponding message are the challenges here.
- Cloud
I like the cloud, but sometimes cloud feels cloudy, cloudier, obscure dust and smog over keywords and hypes and real hard technical features that generate great customer surplius and real cash or quality of business benefits.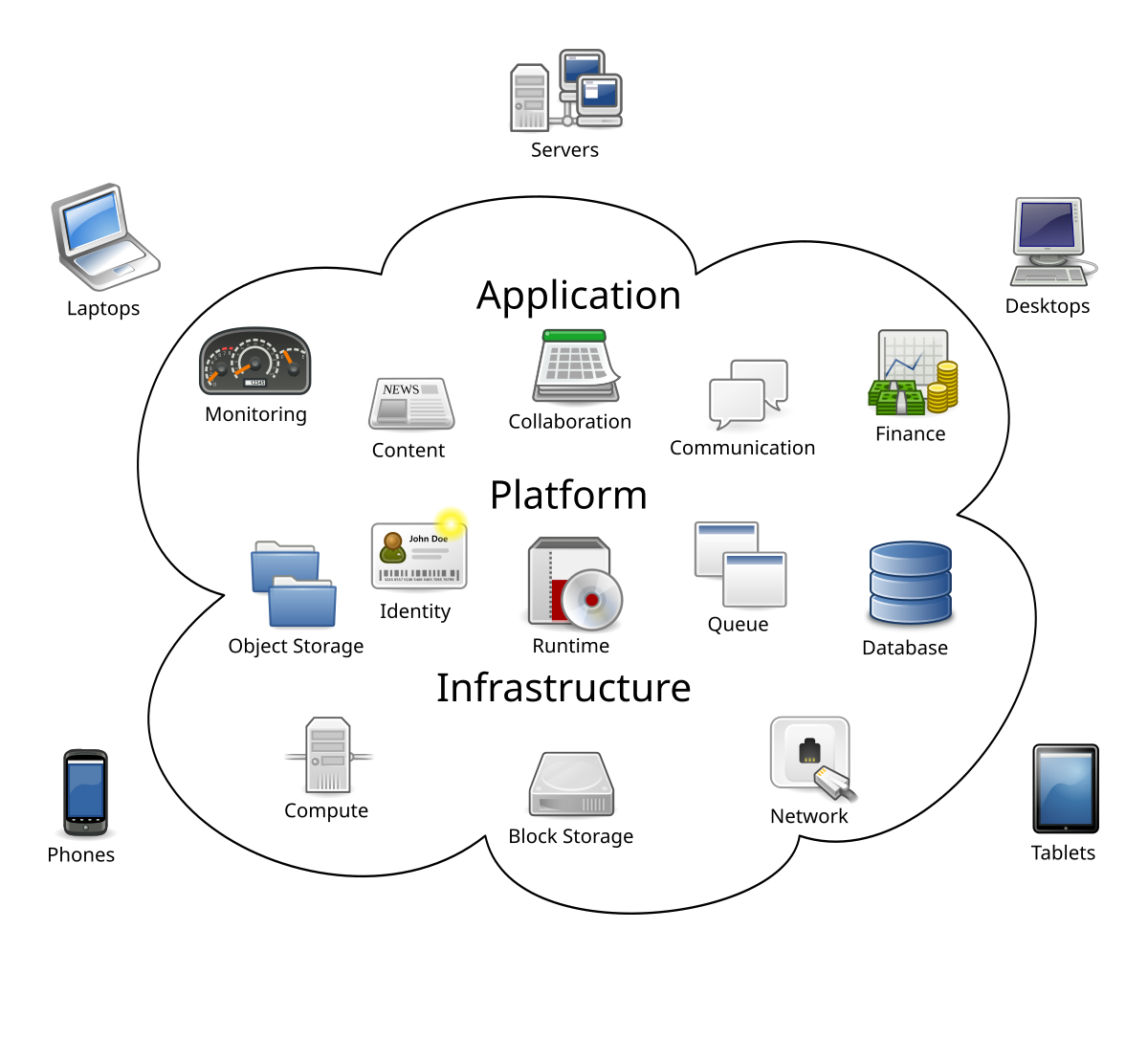
What are the most common problems, pitfalls and misunderstandigs with any cloud?- Lack of specific customer requirements and inaccurate, exact technical specifications from the cloud provider.
Practical example (what I really need and I'm thinking about right now):
I need to implement a state service, that saves current game status of small multiplatform games (e.g. card game schnapsen, archon clone, SUPU) in the cloud. If I play on my android tablet or smartphone, the current state and course of the game will be transfered to a cloud servie, persisted in a cloud storage or database and if I continue playing on Windows desktop, the last state of the game is automatically fetched from the cloud and the game application sets that game state and transferred back to cloud after the next move.
For my purposes the cheapest way will be sufficient:
A simple Amazon Linux 2 AMI (HVM), SSD Volume, Type t2.nano, t2.micro or t2.nano with a simple SQL-Database (no matter if hackish install at virtual imaage or the smallest Amazon DB instance) with somekind of open source PHP Swagger API, like https://github.com/andresharpe/quick-api
With similar requirements, some developers and most managers are probably unsure whether to use Amazon ElasticCache or some kind of Session State Server ported to Azure SQL or entirely another not well known cloud service.
Even fewer people (including myself) know what the exact technical limits of the individual services are, e.g. the exact performance and scalable elasticity of Anazon Elastic Cache and when scalability of Amazon Elastic Cache is completely irrelevant, since the network traffic and the network data volume will always be the bottle neck in that specific scenario. - Nice advertising slogan, but poor performance and poorly configurable options from drive and storage providers, no standard network mount (like SMB or NFS), but a lot of cloudy magic.
When I look at the beautiful Google Drive and Microsoft One Drive, I immediately see that this is not a classic network file system mount under my point of understanding.
Reading and writing large blocks or deep recursively nested directory trees is extremely slow.
I also didn't find an option to have an incremental version history backup created after every change (Create, Delete, Change) to the Cloud Drive or at least simply midnight-generated backups for the last 3 months at low cost.
Options like synchronizing parts of the Cloud Drive locally create horror nightmares.
In 1997 we booted an NFS from the USA via Etherboot with real-time DOS and debugged faster Doom Clones and other 3D games in C ++ with some ASM routines and the network performance didn't fail. - Difficulty finding the most suitable service in Cloud Djungel. Real technical comparisons between the hard facts and the possibilities of the individual cloud services have so far mainly published by free bloggers, e.g. AWS Lambda vs Azure Service Fabric
Decisions are more based on creeds (we have a lot of .NET developers, so we'll use Azure, I mah strong Amazon-like power women and Linux, so I'll use Amazon).
- Lack of specific customer requirements and inaccurate, exact technical specifications from the cloud provider.

Lets go back to RDF in the years 2010 - 2015
You probably know what semantic web, owl, rdf, machine readable & understandable data are, right?
If not, then here is a little bit of reading:
https://www.w3.org/TR/rdf-mt/
https://www.w3.org/TR/2010/WD-rdb2rdf-ucr-20100608/
https://en.wikipedia.org/wiki/RDF_Schema
What does 'going back in time' mean in a large scope and broader sense?
Before all the new trends, there was an attempt to realize semantic web, e.g. RDF as an XML extension with semantic machine-understandable properties.
When we as human beeings read a website or analyze BIG data, we automatically recognize the context, perhaps the meaning and probably the significance of this data.
Machines can't do that, they didn't have a semantic understanding until now.
Information theory distinguishes between 3 levels of information:
- Syntax level (compiler construction, scanner, parser, automata & formal languages, extended grammar, e.g. https://en.wikipedia.org/wiki/Context-free_grammar)
- Semantic level (meaningful reading by people, putting things into context, understanding contexts).
- Pragmatic level (goal-oriented action based on information by recognizing the meaning at the level of semantics).
I assume / postulate:
=> If computer programs reach 2. semantic level => then we are a big step closer to AI realization.
Why computer programs can't already implement semantic understandig?
Theoretically and also practically in terms of technical frameworks, computer programs are already able to understand semantically data.
The concrete problem is here, that too little data are provided in a semantically machine-readable form and a standardized (META-)language.
Somebody has to make here a larger startup, to transform already provided common and needed statistics public data in semantically machine-readable form.
What does that actually bring in return of short time invest?
Not so much immediately!
What could be the fruits in mid-term or in the long tail?
A lot, because when more and more public open data are availible in a semantic machine readable language, programs can also bring some of them in association and we'll be able to implement meta relational AI rules then.
Use case contracts
- employment contracts
- supply contracts
- service provider contracts
- insurance contracts
- bank contracts
- and all the contracts that people sign with just one click on a checkbox (which they usually do not know that this is a legal contract consent).
All clear and understandable so far?
I got this idea when I was looking and inspecting the adopted amendment to the laws and newly passed laws by the democratic republic of Austria and I wanted some semantic automated statistics for some use cases.
For details look at post https://www.facebook.com/heinrich.elsigan.9/posts/156458906318533
or read the post copy below: